Check out the original notebook here.
The goal of this blog is to demonstrate how data augmentation can enhance the development of a model pipeline capable of predicting the sentiment behind customer reviews using both original and engineered features.
The resulting model and dataset will be made available on Hugging Face. If you’re looking for the assets discussed in this blog, you can find them on Hugging Face: e-commerce model and augmented dataset.
The original dataset, Womens Clothing E-Commerce Reviews, is publicly available on Kaggle. You can check out the original dataset here.
1
| dataset_name = "./Womens Clothing E-Commerce Reviews.csv"
|
This dataset contains 23,486 rows and 10 feature variables. Each row represents a customer review and includes the following variables:
- Clothing ID: Integer categorical variable representing the specific item being reviewed.
- Age: Positive integer variable indicating the reviewer’s age.
- Title: String variable containing the title of the review.
- Review Text: String variable for the main content of the review.
- Rating: Positive ordinal integer variable indicating the product rating given by the customer, ranging from 1 (Worst) to 5 (Best).
- Recommended IND: Binary variable indicating whether the customer recommends the product (1 for recommended, 0 for not recommended).
- Positive Feedback Count: Positive integer capturing the number of other customers who found the review helpful.
- Division Name: Categorical variable representing the high-level division of the product.
- Department Name: Categorical variable for the department the product belongs to.
- Class Name: Categorical variable representing the product’s class name.
Hidden code
Import common libraries that usually are in any Python environment.
1
2
3
4
| import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import os
|
In case of running the notebook in Google Colab we need to install some libraries that are not there…
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| try:
import google.colab
from google.colab import files
IN_COLAB = True
except:
IN_COLAB = False
def upload_env_file():
files.upload()
if not os.path.exists('.env'):
raise('Exception: .env file not uploaded on working area')
def load_env_variables():
from dotenv import load_dotenv
if not os.path.exists('.env'):
raise('Exception: .env file not found on working area')
load_dotenv()
def login_huggingface_hub():
from huggingface_hub import login
hf_token = os.environ['HF_TOKEN']
login(hf_token)
def install_packages():
print('Installing packages...')
!curl -O https://raw.githubusercontent.com/wilberquito/women-e-commerce-opinion/main/requirements.txt
!pip install -r requirements.txt
def download_data():
print('Downloading dataset...')
!curl -O https://raw.githubusercontent.com/wilberquito/women-e-commerce-opinion/main/scripts/download-data.sh
!chmod +x download-data.sh
!./download-data.sh
if IN_COLAB:
install = input('Install Python packages [Y/n]: ')
if install == 'Y':
install_packages()
if not os.path.exists('.env'):
upload_env_file()
load_env_variables()
login_huggingface_hub()
if not os.path.exists(dataset_name):
download_data()
|
Install Python packages [Y/n]: Y
Installing packages...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 160 100 160 0 0 896 0 --:--:-- --:--:-- --:--:-- 898
The token has not been saved to the git credentials helper. Pass `add_to_git_credential=True` in this function directly or `--add-to-git-credential` if using via `huggingface-cli` if you want to set the git credential as well.
Token is valid (permission: write).
Your token has been saved to /root/.cache/huggingface/token
Login successful
Other libraries that are no available in the environment after installing them from requirements.txt.
1
2
3
4
5
6
| from sklearn.model_selection import train_test_split
from datasets import Dataset, DatasetDict
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, Seq2SeqTrainingArguments, Seq2SeqTrainer
from transformers import pipeline
import torch
|
Data analysis
1
2
3
4
5
| cols = pd.read_csv(dataset_name, nrows=1).columns
reviews_df = pd.read_csv(dataset_name, usecols=cols[1:])
cols = [col.lower() for col in reviews_df.columns]
reviews_df.columns = cols
reviews_df.head()
|
| | clothing id | age | title | review text | rating | recommended ind | positive feedback count | division name | department name | class name |
|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf… | 4 | 1 | 0 | Initmates | Intimate | Intimates |
| 1 | 1080 | 34 | NaN | Love this dress! it’s sooo pretty. i happene… | 5 | 1 | 4 | General | Dresses | Dresses |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall… | 3 | 0 | 0 | General | Dresses | Dresses |
| 3 | 1049 | 50 | My favorite buy! | I love, love, love this jumpsuit. it’s fun, fl… | 5 | 1 | 0 | General Petite | Bottoms | Pants |
| 4 | 847 | 47 | Flattering shirt | This shirt is very flattering to all due to th… | 5 | 1 | 6 | General | Tops | Blouses |
(23486, 10)
| | clothing id | age | rating | recommended ind | positive feedback count |
|---|
| count | 23486.000000 | 23486.000000 | 23486.000000 | 23486.000000 | 23486.000000 |
| mean | 918.118709 | 43.198544 | 4.196032 | 0.822362 | 2.535936 |
| std | 203.298980 | 12.279544 | 1.110031 | 0.382216 | 5.702202 |
| min | 0.000000 | 18.000000 | 1.000000 | 0.000000 | 0.000000 |
| 25% | 861.000000 | 34.000000 | 4.000000 | 1.000000 | 0.000000 |
| 50% | 936.000000 | 41.000000 | 5.000000 | 1.000000 | 1.000000 |
| 75% | 1078.000000 | 52.000000 | 5.000000 | 1.000000 | 3.000000 |
| max | 1205.000000 | 99.000000 | 5.000000 | 1.000000 | 122.000000 |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 23486 entries, 0 to 23485
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 clothing id 23486 non-null int64
1 age 23486 non-null int64
2 title 19676 non-null object
3 review text 22641 non-null object
4 rating 23486 non-null int64
5 recommended ind 23486 non-null int64
6 positive feedback count 23486 non-null int64
7 division name 23472 non-null object
8 department name 23472 non-null object
9 class name 23472 non-null object
dtypes: int64(5), object(5)
memory usage: 1.8+ MB
Binning rating
1
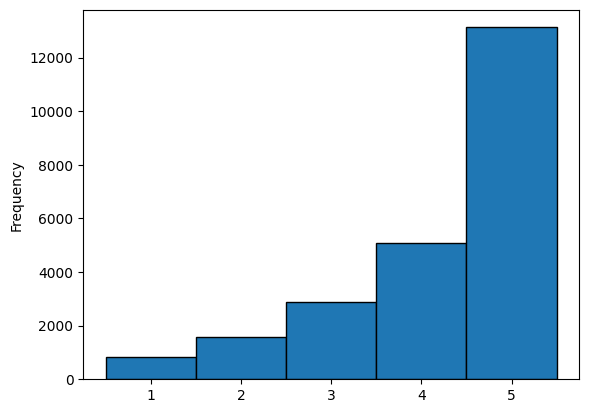
| reviews_df["rating"].value_counts()
|
| | count |
|---|
| 5 | 13131 |
| 4 | 5077 |
| 3 | 2871 |
| 2 | 1565 |
| 1 | 842 |
1
2
| ax = reviews_df["rating"].plot(kind="hist", bins=np.arange(0, 6) + 0.5, ec='k')
plt.show()
|
Distribution of ratings
Creating a model that predicts ratings based on reviews is challenging with the previous distribution. To address this, rather than predicting a rating between 1 and 5, let’s simplify it by predicting a value between 1 and 3: where 1 indicates the user is dissatisfied, 2 indicates satisfaction, and 3 indicates the user loves the product.
1
2
3
4
5
6
7
8
9
10
| def soft_rating(rating):
new_rating = 3
if rating <= 3:
new_rating = 1
elif rating <= 4:
new_rating = 2
return new_rating
reviews_df["soft rating"] = reviews_df["rating"].map(soft_rating)
reviews_df.head()
|
| | clothing id | age | title | review text | rating | recommended ind | positive feedback count | division name | department name | class name | soft rating |
|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf… | 4 | 1 | 0 | Initmates | Intimate | Intimates | 2 |
| 1 | 1080 | 34 | NaN | Love this dress! it’s sooo pretty. i happene… | 5 | 1 | 4 | General | Dresses | Dresses | 3 |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall… | 3 | 0 | 0 | General | Dresses | Dresses | 1 |
| 3 | 1049 | 50 | My favorite buy! | I love, love, love this jumpsuit. it’s fun, fl… | 5 | 1 | 0 | General Petite | Bottoms | Pants | 3 |
| 4 | 847 | 47 | Flattering shirt | This shirt is very flattering to all due to th… | 5 | 1 | 6 | General | Tops | Blouses | 3 |
1
| reviews_df["soft rating"].value_counts()
|
1
2
| ax = reviews_df["soft rating"].plot(kind="hist", bins=np.arange(0, 4) + 0.5, ec="k")
plt.show()
|
Distribution of softed rating
Removing useless data
It would be helpful to determine if any features in the dataset are relevant. We can do this by first examining the linear correlation between soft rating and the other features.
1
2
3
4
| numeric_reviews_df = reviews_df.select_dtypes(include="number").drop(
labels=["clothing id"], axis=1
)
numeric_reviews_df.corr()
|
| | age | rating | recommended ind | positive feedback count | soft rating |
|---|
| age | 1.000000 | 0.026831 | 0.030622 | 0.043079 | 0.036042 |
| rating | 0.026831 | 1.000000 | 0.792336 | -0.064961 | 0.941389 |
| recommended ind | 0.030622 | 0.792336 | 1.000000 | -0.069045 | 0.726893 |
| positive feedback count | 0.043079 | -0.064961 | -0.069045 | 1.000000 | -0.062530 |
| soft rating | 0.036042 | 0.941389 | 0.726893 | -0.062530 | 1.000000 |
From this information, it’s evident that the positive feedback count is more of a hindrance than a help. Additionally, it doesn’t directly reflect the user’s opinion but rather how others have interpreted it.
1
2
| reviews_df = reviews_df.drop(labels=["positive feedback count"], axis=1, errors='ignore')
reviews_df.head(3)
|
| | clothing id | age | title | review text | rating | recommended ind | division name | department name | class name | soft rating |
|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf… | 4 | 1 | Initmates | Intimate | Intimates | 2 |
| 1 | 1080 | 34 | NaN | Love this dress! it’s sooo pretty. i happene… | 5 | 1 | General | Dresses | Dresses | 3 |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall… | 3 | 0 | General | Dresses | Dresses | 1 |
1
| reviews_df['division name'].value_counts()
|
| | count |
|---|
| General | 13850 |
| General Petite | 8120 |
| Initmates | 1502 |
1
| reviews_df['department name'].value_counts()
|
| | count |
|---|
| Tops | 10468 |
| Dresses | 6319 |
| Bottoms | 3799 |
| Intimate | 1735 |
| Jackets | 1032 |
| Trend | 119 |
1
| reviews_df['class name'].value_counts()
|
| | count |
|---|
| Dresses | 6319 |
| Knits | 4843 |
| Blouses | 3097 |
| Sweaters | 1428 |
| Pants | 1388 |
| Jeans | 1147 |
| Fine gauge | 1100 |
| Skirts | 945 |
| Jackets | 704 |
| Lounge | 691 |
| Swim | 350 |
| Outerwear | 328 |
| Shorts | 317 |
| Sleep | 228 |
| Legwear | 165 |
| Intimates | 154 |
| Layering | 146 |
| Trend | 119 |
| Casual bottoms | 2 |
| Chemises | 1 |
The features division name, department name, and class name could be useful, but their distribution is highly skewed. To simplify the analysis, I’ve decided to take a different approach and drop them.
1
2
| reviews_df = reviews_df.drop(labels=['division name', 'department name', 'class name'], axis=1, errors='ignore')
reviews_df.head(3)
|
| | clothing id | age | title | review text | rating | recommended ind | soft rating |
|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf… | 4 | 1 | 2 |
| 1 | 1080 | 34 | NaN | Love this dress! it’s sooo pretty. i happene… | 5 | 1 | 3 |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall… | 3 | 0 | 1 |
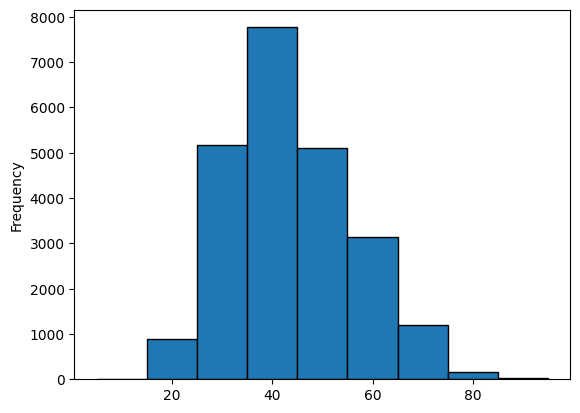
Binning age
1
2
3
4
5
| spam = 10
spam_window = spam / 2
limit = int(100 / spam)
bins = np.array([x*spam for x in range(limit)]) + spam_window
bins
|
array([ 5., 15., 25., 35., 45., 55., 65., 75., 85., 95.])
1
| np.histogram(reviews_df['age'], bins = bins)
|
(array([ 0, 892, 5175, 7771, 5110, 3152, 1193, 161, 30]),
array([ 5., 15., 25., 35., 45., 55., 65., 75., 85., 95.]))
1
2
| reviews_df['age'].plot(kind='hist', bins=bins, ec='k')
plt.show()
|
1
2
3
4
5
6
7
8
9
10
| def soft_age(age):
generation = 3
if age < 35:
generation = 1
elif age < 55:
generation = 2
return generation
reviews_df['generation'] = reviews_df['age'].map(soft_age)
reviews_df.head(3)
|
| | clothing id | age | title | review text | rating | recommended ind | soft rating | generation |
|---|
| 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf… | 4 | 1 | 2 | 1 |
| 1 | 1080 | 34 | NaN | Love this dress! it’s sooo pretty. i happene… | 5 | 1 | 3 | 1 |
| 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall… | 3 | 0 | 1 | 3 |
1
| reviews_df['generation'].value_counts()
|
Check out missing values
1
| reviews_df.isna().any()
|
| | 0 |
|---|
| clothing id | False |
| age | False |
| title | True |
| review text | True |
| rating | False |
| recommended ind | False |
| soft rating | False |
| generation | False |
There are some missing values! Let’s figure it out how many for each feature.
1
| reviews_df.isna().sum()
|
| | 0 |
|---|
| clothing id | 0 |
| age | 0 |
| title | 3810 |
| review text | 845 |
| rating | 0 |
| recommended ind | 0 |
| soft rating | 0 |
| generation | 0 |
Well, what about the $\%$ of missing values to respect the hole dataset?
1
| (reviews_df.isna().sum() * 100) / reviews_df.shape[0]
|
| | 0 |
|---|
| clothing id | 0.000000 |
| age | 0.000000 |
| title | 16.222430 |
| review text | 3.597888 |
| rating | 0.000000 |
| recommended ind | 0.000000 |
| soft rating | 0.000000 |
| generation | 0.000000 |
What concerns me the most is the $16\%$ of missing values for titles. However, the more significant issue is the approximately $3.6\%$ of missing descriptions. Titles can be generated as summaries of the descriptions, but not the other way around.
1
2
3
| reviews_df = reviews_df[~reviews_df['review text'].isna()]
reviews_df = reviews_df.reset_index()
reviews_df.head(3)
|
| | index | clothing id | age | title | review text | rating | recommended ind | soft rating | generation |
|---|
| 0 | 0 | 767 | 33 | NaN | Absolutely wonderful - silky and sexy and comf… | 4 | 1 | 2 | 1 |
| 1 | 1 | 1080 | 34 | NaN | Love this dress! it’s sooo pretty. i happene… | 5 | 1 | 3 | 1 |
| 2 | 2 | 1077 | 60 | Some major design flaws | I had such high hopes for this dress and reall… | 3 | 0 | 1 | 3 |
After removing the samples without descriptions, the number of missing titles decreased, but there are still many reviews without a title.
1
| (reviews_df.isna().sum() * 100) / reviews_df.shape[0]
|
| | 0 |
|---|
| index | 0.000000 |
| clothing id | 0.000000 |
| age | 0.000000 |
| title | 13.100128 |
| review text | 0.000000 |
| rating | 0.000000 |
| recommended ind | 0.000000 |
| soft rating | 0.000000 |
| generation | 0.000000 |
1
| reviews_df['title'].head(3)
|
| | title |
|---|
| 0 | NaN |
| 1 | NaN |
| 2 | Some major design flaws |
Select features
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| features = [
'clothing id',
'title',
'review text',
'soft rating',
'recommended ind',
'generation'
]
reviews_df['soft rating'] = reviews_df['soft rating'].astype('category')
reviews_df['generation'] = reviews_df['generation'].astype('category')
reviews_df = reviews_df[features]
reviews_df.head(3)
|
| | clothing id | title | review text | soft rating | recommended ind | generation |
|---|
| 0 | 767 | NaN | Absolutely wonderful - silky and sexy and comf… | 2 | 1 | 1 |
| 1 | 1080 | NaN | Love this dress! it’s sooo pretty. i happene… | 3 | 1 | 1 |
| 2 | 1077 | Some major design flaws | I had such high hopes for this dress and reall… | 1 | 0 | 3 |
| | 0 |
|---|
| clothing id | int64 |
| title | object |
| review text | object |
| soft rating | category |
| recommended ind | int64 |
| generation | category |
T5 is a text-to-text transform framework capable to do machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). If you want to know more about this framework consult it here as A Shared Text-To-Text Framework.
In this case we will fine-tune the transformer in order to provide good summarizations.
Generating datasets
Hidden code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| def generate_datasets(reviews, test_size=0.2, stratify='soft rating'):
titled_reviews = reviews[~reviews['title'].isna()]
infer_reviews = reviews[reviews['title'].isna()]
train, test = train_test_split(
titled_reviews,
test_size=test_size,
stratify=titled_reviews[stratify],
random_state=42
)
datasets = [Dataset.from_pandas(df) for df in [train, test, infer_reviews]]
dataset_names = ['train', 'test', 'infer']
dict_datasets = dict(zip(dataset_names, datasets))
train_datasets = DatasetDict(
{
'train': dict_datasets['train'],
'test': dict_datasets['test']
}
)
infer_dataset = dict_datasets['infer']
return train_datasets, infer_dataset
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| def preprocess_function(examples):
prefix = "summarize: "
inputs = [prefix + doc for doc in examples["review text"]]
model_inputs = tokenizer(
inputs, max_length=1024,
truncation=True,
padding='max_length',
return_tensors='pt'
)
labels = tokenizer(
text_target=examples["title"],
max_length=128,
truncation=True,
padding='max_length',
return_tensors="pt"
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def compute_metrics(eval_pred):
import evaluate
predictions, labels = eval_pred
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
rouge = evaluate.load("rouge")
result = rouge.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
result["gen_len"] = np.mean(prediction_lens)
return {k: round(v, 4) for k, v in result.items()}
|
1
2
| train_datasets, infer_dataset = generate_datasets(reviews_df)
train_datasets, infer_dataset
|
(DatasetDict({
train: Dataset({
features: ['clothing id', 'title', 'review text', 'soft rating', 'recommended ind', 'generation', '__index_level_0__'],
num_rows: 15740
})
test: Dataset({
features: ['clothing id', 'title', 'review text', 'soft rating', 'recommended ind', 'generation', '__index_level_0__'],
num_rows: 3935
})
}),
Dataset({
features: ['clothing id', 'title', 'review text', 'soft rating', 'recommended ind', 'generation', '__index_level_0__'],
num_rows: 2966
}))
1
2
| checkpoint = "google-t5/t5-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
|
tokenizer_config.json: 0%| | 0.00/2.32k [00:00<?, ?B/s]
spiece.model: 0%| | 0.00/792k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/1.39M [00:00<?, ?B/s]
1
2
3
| batch_size = 256
batched = True
train_datasets = train_datasets.map(preprocess_function, batch_size=batch_size, batched=batched)
|
Map: 0%| | 0/15740 [00:00<?, ? examples/s]
Map: 0%| | 0/3935 [00:00<?, ? examples/s]
Fine-tuning t5-small
1
2
| model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
model
|
config.json: 0%| | 0.00/1.21k [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/242M [00:00<?, ?B/s]
generation_config.json: 0%| | 0.00/147 [00:00<?, ?B/s]
T5ForConditionalGeneration(
(shared): Embedding(32128, 512)
(encoder): T5Stack(
(embed_tokens): Embedding(32128, 512)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
(relative_attention_bias): Embedding(32, 8)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-5): 5 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(decoder): T5Stack(
(embed_tokens): Embedding(32128, 512)
(block): ModuleList(
(0): T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
(relative_attention_bias): Embedding(32, 8)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1-5): 5 x T5Block(
(layer): ModuleList(
(0): T5LayerSelfAttention(
(SelfAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): T5LayerCrossAttention(
(EncDecAttention): T5Attention(
(q): Linear(in_features=512, out_features=512, bias=False)
(k): Linear(in_features=512, out_features=512, bias=False)
(v): Linear(in_features=512, out_features=512, bias=False)
(o): Linear(in_features=512, out_features=512, bias=False)
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): T5LayerFF(
(DenseReluDense): T5DenseActDense(
(wi): Linear(in_features=512, out_features=2048, bias=False)
(wo): Linear(in_features=2048, out_features=512, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
(act): ReLU()
)
(layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(final_layer_norm): T5LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(lm_head): Linear(in_features=512, out_features=32128, bias=False)
)
1
| torch.cuda.is_available()
|
True
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| if torch.cuda.is_available():
torch.cuda.empty_cache()
data_collator = DataCollatorForSeq2Seq(tokenizer=tokenizer, model=checkpoint)
batch_size = 16
learning_rate = 2e-5
weight_decay = 0.01
epochs = 1
training_args = Seq2SeqTrainingArguments(
output_dir="e-comerce",
eval_strategy="steps",
learning_rate=learning_rate,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=weight_decay,
save_total_limit=3,
num_train_epochs=epochs,
predict_with_generate=True,
fp16=True,
push_to_hub=True,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_datasets["train"],
eval_dataset=train_datasets["test"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
|
| Step | Training Loss | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|---|
| 500 | 0.433200 | 0.195895 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
TrainOutput(global_step=984, training_loss=0.32267741846844433, metrics={'train_runtime': 1143.418, 'train_samples_per_second': 13.766, 'train_steps_per_second': 0.861, 'total_flos': 4260559910338560.0, 'train_loss': 0.32267741846844433, 'epoch': 1.0})
Data agumentation using the t5-small fine-tuned
In this section we will se how to re-use the fine tuned model in the previous section to generete summaries as titles given the descriptions of the dataset.
1
2
| text = "summarize: The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country. It'll lower the deficit and ask the ultra-wealthy and corporations to pay their fair share. And no one making under $400,000 per year will pay a penny more in taxes."
text
|
"summarize: The Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs. It's the most aggressive action on tackling the climate crisis in American history, which will lift up American workers and create good-paying, union jobs across the country. It'll lower the deficit and ask the ultra-wealthy and corporations to pay their fair share. And no one making under $400,000 per year will pay a penny more in taxes."
In the following line you can check the embeddings generated by the text
1
2
3
| tokenizer = AutoTokenizer.from_pretrained("wilberquito/e-comerce")
inputs = tokenizer(text, return_tensors="pt").input_ids
inputs
|
tensor([[21603, 10, 37, 86, 89, 6105, 419, 8291, 1983, 1364,
7, 7744, 2672, 1358, 6, 533, 124, 1358, 6, 11,
827, 1358, 5, 94, 31, 7, 8, 167, 8299, 1041,
30, 3, 26074, 8, 3298, 5362, 16, 797, 892, 6,
84, 56, 5656, 95, 797, 2765, 11, 482, 207, 18,
8832, 53, 6, 7021, 2476, 640, 8, 684, 5, 94,
31, 195, 1364, 8, 11724, 11, 987, 8, 6173, 18,
1123, 138, 189, 63, 11, 11711, 12, 726, 70, 2725,
698, 5, 275, 150, 80, 492, 365, 1514, 31471, 399,
215, 56, 726, 3, 9, 23925, 72, 16, 5161, 5,
1]])
1
2
| summarizer = pipeline("summarization", model="wilberquito/e-comerce", min_length=5, max_length=30)
summarizer(text)
|
Hardware accelerator e.g. GPU is available in the environment, but no `device` argument is passed to the `Pipeline` object. Model will be on CPU.
[{'summary_text': 'Inflation Reduction Act lowers prescription drug costs, health care costs, and energy costs .'}]
Hidden code
1
2
3
4
5
6
7
| def title_data_augmentation(summarizer, batch):
reviews = batch['review text']
summaries = summarizer(reviews)
summaries = [summary['summary_text'] for summary in summaries]
return {
'title': summaries
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| summarization_kwargs = {
'min_length': 4,
'max_length': 16,
'device': 'cuda' if torch.cuda.is_available() else 'cpu'
}
summarizer = pipeline(
"summarization",
model="wilberquito/e-comerce",
**summarization_kwargs
)
infer_dataset = infer_dataset.map(
lambda batch: title_data_augmentation(summarizer, batch),
batched=True, batch_size=256
)
for data in infer_dataset:
print(data)
break
|
{'clothing id': 767, 'title': 'Beautiful and sexy', 'review text': 'Absolutely wonderful - silky and sexy and comfortable', 'soft rating': 2, 'recommended ind': 1, 'generation': 1, '__index_level_0__': 0}
Publish the agumented dataset in Hugging Face
1
2
| infer_df = pd.DataFrame(infer_dataset)
infer_df.head(3)
|
| | clothing id | title | review text | soft rating | recommended ind | generation | index_level_0 |
|---|
| 0 | 767 | Beautiful and sexy | Absolutely wonderful - silky and sexy and comf… | 2 | 1 | 1 | 0 |
| 1 | 1080 | Love this dress! | Love this dress! it’s sooo pretty. i happene… | 3 | 1 | 1 | 1 |
| 2 | 1095 | Beautiful dress! | This dress is perfection! so pretty and flatte… | 3 | 1 | 2 | 11 |
1
2
| train_df = pd.DataFrame(train_datasets['train'])
train_df.head(3)
|
| | clothing id | title | review text | soft rating | recommended ind | generation | index_level_0 |
|---|
| 0 | 835 | Gorgeous top! | I’m obsessed with this top! i got it for chris… | 3 | 1 | 3 | 18003 |
| 1 | 42 | Lovely | Makes me feel like a sexy ice skater. true to … | 3 | 1 | 1 | 18273 |
| 2 | 860 | Classic stripes | I do not know if this item is worth the full p… | 2 | 1 | 3 | 7611 |
1
2
| test_df = pd.DataFrame(train_datasets['test'])
test_df.head(3)
|
| | clothing id | title | review text | soft rating | recommended ind | generation | index_level_0 |
|---|
| 0 | 1095 | Elegant! | I purchased this in london, early april, and i… | 3 | 1 | 3 | 17402 |
| 1 | 830 | Lampshade | If you like to wear lampshades this is the shi… | 1 | 0 | 2 | 19915 |
| 2 | 829 | Maeve tunic | I bought this tunic today because it paired we… | 3 | 1 | 3 | 4001 |
1
2
3
| dataset_df = pd.concat([infer_df, train_df, test_df])
dataset_df = dataset_df.drop(['__index_level_0__'], axis=1)
dataset_df.head(3)
|
| | clothing id | title | review text | soft rating | recommended ind | generation |
|---|
| 0 | 767 | Beautiful and sexy | Absolutely wonderful - silky and sexy and comf… | 2 | 1 | 1 |
| 1 | 1080 | Love this dress! | Love this dress! it’s sooo pretty. i happene… | 3 | 1 | 1 |
| 2 | 1095 | Beautiful dress! | This dress is perfection! so pretty and flatte… | 3 | 1 | 2 |
Hidden code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def generate_e_commerce_datasets(reviews, test_size=0.2, stratify='soft rating'):
train_df, test_df = train_test_split(
reviews,
test_size=test_size,
stratify=reviews[stratify],
random_state=42
)
datasets = DatasetDict(
{
'train': Dataset.from_pandas(train_df),
'test': Dataset.from_pandas(test_df)
}
)
return datasets
|
1
2
| e_commerce_datasets = generate_e_commerce_datasets(dataset_df)
e_commerce_datasets
|
DatasetDict({
train: Dataset({
features: ['clothing id', 'title', 'review text', 'soft rating', 'recommended ind', 'generation', '__index_level_0__'],
num_rows: 18112
})
test: Dataset({
features: ['clothing id', 'title', 'review text', 'soft rating', 'recommended ind', 'generation', '__index_level_0__'],
num_rows: 4529
})
})
1
| e_commerce_datasets.push_to_hub('wilberquito/processed_women_clothing_e_commerce_opinions')
|
Uploading the dataset shards: 0%| | 0/1 [00:00<?, ?it/s]
Creating parquet from Arrow format: 0%| | 0/19 [00:00<?, ?ba/s]
Uploading the dataset shards: 0%| | 0/1 [00:00<?, ?it/s]
Creating parquet from Arrow format: 0%| | 0/5 [00:00<?, ?ba/s]
README.md: 0%| | 0.00/24.0 [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/datasets/wilberquito/processed_women_clothing_e_commerce_opinions/commit/44fc5121c2a7926f18e558f8f13cc11de7d1458b', commit_message='Upload dataset', commit_description='', oid='44fc5121c2a7926f18e558f8f13cc11de7d1458b', pr_url=None, pr_revision=None, pr_num=None)
 Distribution of ratings
Distribution of ratings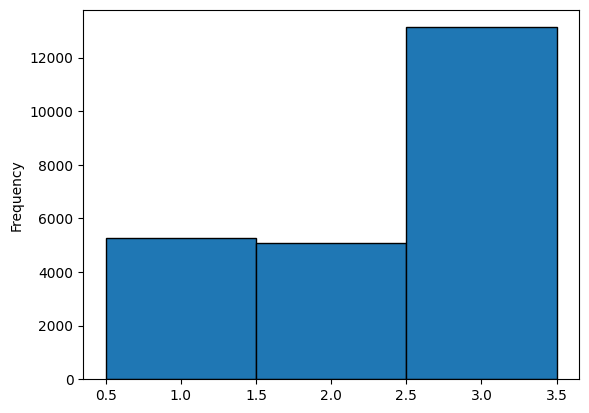 Distribution of softed rating
Distribution of softed rating